ما هو أفضل ذكاء اصطناعي للإجابة عن الأسئلة العلمية الصعبة والمحيّرة، بلغة مبسطة لغير المتخصص
ا.د. حسن محمود موسى ابو المعالي
- ملخص تنفيذي
إذا كان السؤال العلمي سهلًا أو معروف الجواب، فالكثير من نماذج الذكاء الاصطناعي تستطيع أن تعطي إجابة جيدة. لكن إذا كان السؤال معقدًا جدًا أو ما تزال إجابته غير محسومة علميًا، فلا يوجد اليوم نموذج واحد يمكن اعتباره الأفضل دائمًا في كل الحالات. الأدلة الحديثة تشير إلى أن الأفضل غالبًا ليس “برنامج دردشة واحد”، بل نظام ذكي متكامل يستطيع أن يفكر، ويبحث في المصادر العلمية، ويستخدم أدوات، ثم يراجع إجابته قبل أن يقدمها.
بصورة مبسطة، الترتيب الأقرب للواقع هو كالتالي:
الأنظمة الذكية المرتبطة بأدوات ومراجع علمية وتحقق خارجي
نماذج الذكاء الاصطناعي القوية المصممة للاستدلال العميق
النماذج المتخصصة في مجال علمي محدد، مثل الطب أو الأعصاب أو الكيمياء
النماذج العامة الكبيرة متعددة الوسائط
النماذج المفتوحة الأساسية غير المتخصصة
السبب بسيط، كلما كان السؤال العلمي أكثر صعوبة، زادت الحاجة إلى البحث والتحقق والمقارنة بين الأدلة، لا إلى مجرد “إجابة سريعة”. - المقدمة
كثير من الناس يسألون، ما هو أفضل ذكاء اصطناعي إذا أردت أن أسأله سؤالًا علميًا محيرًا، مثل:
لماذا اختلفت نتائج الدراسات حول علاج معيّن؟
ما التفسير الأرجح لظاهرة بيولوجية ما تزال غير مفهومة جيدًا؟
أي فرضية علمية تبدو أقوى عندما تكون الأدلة متعارضة؟
هل هذا الاكتشاف الجديد قوي فعلًا، أم مجرد نتيجة أولية؟
هذه ليست أسئلة معلومات عامة. هذه أسئلة تحتاج إلى فهم، وتحليل، ومقارنة بين الأدلة، ومعرفة حدود اليقين العلمي. وهنا تظهر المشكلة، كثير من أنظمة الذكاء الاصطناعي قد تتكلم بثقة حتى عندما تكون غير متأكدة. لذلك يجب أن يكون السؤال الحقيقي ليس فقط: “من يجيب أسرع؟” بل: من يجيب بشكل أدق وأكثر حذرًا عندما يكون الجواب غير واضح أصلًا؟ - الفكرة الأساسية التي يجب فهمها أولًا
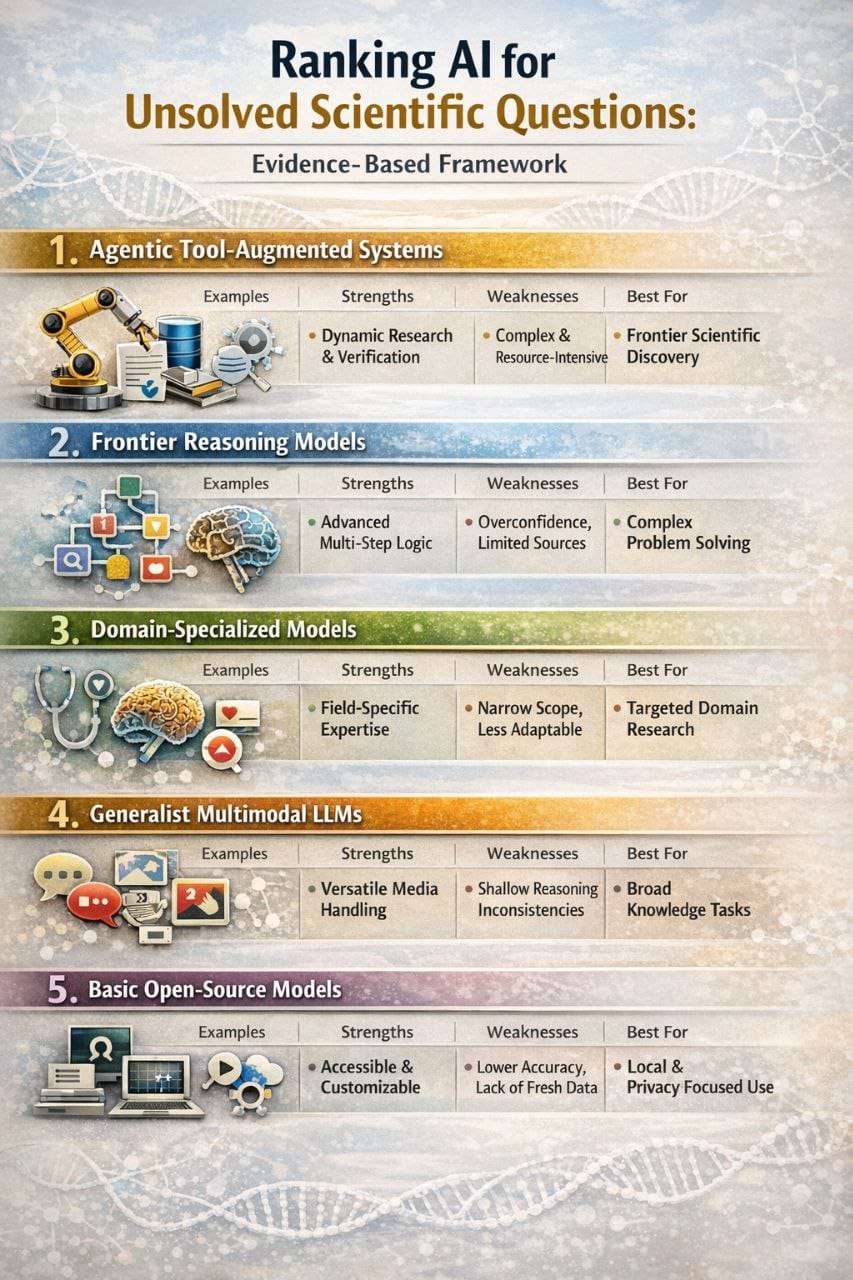
لفهم الموضوع بسهولة، يمكن تقسيم أنظمة الذكاء الاصطناعي العلمية إلى خمس فئات رئيسية.
3.1 الفئة الأولى، أنظمة ذكية تستخدم أدوات ومصادر وتحقق
هذه ليست مجرد روبوتات محادثة. هذه أنظمة تستطيع أن:
تبحث في الأدبيات العلمية
تقرأ مصادر حديثة
تستعمل أدوات حسابية أو تحليلية
تقارن النتائج
تراجع الإجابة قبل إخراجها
هذه الفئة هي الأقوى عادة عندما يكون السؤال العلمي صعبًا جدًا أو مفتوحًا أو غير محسوم، لأن المشكلة هنا ليست في “حفظ المعلومات”، بل في طريقة العمل نفسها. الدراسات الحديثة تشير إلى أن الأنظمة الوكيلة، agentic systems، أصبحت أكثر أهمية من النموذج وحده في المهام العلمية الصعبة.
3.2 الفئة الثانية، نماذج الاستدلال القوية
هذه النماذج مصممة لتفكر بخطوات أكثر، وتحلل المسائل المعقدة بشكل أفضل من النماذج التقليدية. وهي مفيدة جدًا في الأسئلة التي تحتاج:
ربط عدة أفكار معًا
استبعاد الاحتمالات الضعيفة
بناء تفسير منطقي متعدد الخطوات
لكنها ما تزال تعاني أحيانًا من الثقة الزائدة أو من تقديم جواب يبدو منطقيًا لكنه غير مدعوم بما يكفي من الأدلة.
3.3 الفئة الثالثة، النماذج المتخصصة
هذه نماذج دُرّبت أو ضُبطت على مجال معين مثل الطب أو الكيمياء أو علم الأعصاب. ميزتها أنها تفهم لغة المجال ومشكلاته بصورة أدق. لكنها قد تكون قوية داخل مجالها فقط، وأضعف خارجه. كما أن التخصص لا يعني دائمًا أنها أفضل من النموذج العام في كل سيناريو.
3.4 الفئة الرابعة، النماذج العامة الكبيرة
هذه النماذج معروفة لدى كثير من المستخدمين. وهي ممتازة في الشرح، والتلخيص، والصياغة، والإجابة عن كثير من الأسئلة العامة والعلمية. لكنها عندما تواجه أسئلة علمية شديدة التعقيد أو غير محسومة، قد تحتاج إلى دعم خارجي بالمراجع والأدوات، وإلا فإنها قد تعطي إجابات تبدو مقنعة أكثر مما ينبغي.
3.5 الفئة الخامسة، النماذج المفتوحة الأساسية
هذه مفيدة من ناحية الإتاحة والخصوصية والتخصيص المحلي، لكنها في صورتها الأساسية، من دون تدريب إضافي أو استرجاع للمراجع أو بنية تحقق، تكون عادة أقل دقة من الفئات الأعلى في التعامل مع الأسئلة العلمية المحيرة. - الترتيب التنازلي بصورة مبسطة
4.1 المرتبة الأولى، الأنظمة الذكية المدعومة بالأدوات والمراجع والتحقق
هذه هي الأفضل عادة في الأسئلة العلمية المحيرة.
السبب أن السؤال العلمي غير المعروف لا يحتاج فقط إلى “ذاكرة”، بل يحتاج إلى:
الوصول إلى أحدث الدراسات
مقارنة الأدلة
معرفة ما إذا كانت النتائج متفقة أو متناقضة
تمييز ما هو ثابت مما هو أولي أو غير محسوم
الاعتراف عندما تكون الإجابة غير مؤكدة
مثلًا، في الكيمياء أظهرت دراسات أن دمج النماذج اللغوية مع أدوات تخصصية جعلها أكثر قدرة على إنجاز مهام علمية لم تكن تنجح فيها بالاعتماد على اللغة وحدها. وفي الطب، تشير الدراسات الحديثة إلى أن الأنظمة الوكيلة التي تجمع بين التخطيط والبحث والتحقق أكثر ملاءمة للمهام السريرية المعقدة من نموذج محادثة يعمل وحده.
الخلاصة المبسطة: إذا كان السؤال العلمي فعلا محيرًا، فالأفضل هو النظام الذي يبحث ويتحقق، لا النظام الذي يجيب مباشرة فقط.
4.2 المرتبة الثانية، نماذج الاستدلال القوية
هذه النماذج ممتازة عندما يحتاج السؤال إلى تفكير منطقي عميق، مثل:
تحليل فرضيتين متنافستين
تفسير تناقض في النتائج
بناء سلسلة سببية
حل مشكلة متعددة المراحل
لكن الدراسات الحديثة أوضحت أيضًا أن هذه النماذج قد تبقى ضعيفة عندما تتطلب المهمة توثيقًا حقيقيًا أو أدلة حديثة أو خطوات تحقق خارجية. كما أن بعض الاختبارات العلمية شديدة الصعوبة أظهرت أن أقوى النماذج الحالية ما تزال بعيدة عن مستوى الخبير الأكاديمي في أصعب الأسئلة.
الخلاصة المبسطة: هذه النماذج جيدة جدًا في التفكير، لكنها ليست كافية وحدها إذا كان المطلوب جوابًا علميًا حساسًا أو غير محسوم.
4.3 المرتبة الثالثة، النماذج المتخصصة في مجال محدد
هذه تكون مفيدة جدًا عندما يكون السؤال داخل مجال ضيق، مثل:
سؤال طبي معقد
سؤال في الأعصاب
سؤال في الكيمياء
سؤال في المعلوماتية الحيوية
هناك دراسات أظهرت أن نماذج متخصصة استطاعت أداءً قويًا جدًا، بل تفوقت في بعض المهام على خبراء بشريين أو على نماذج عامة، خاصة عندما كانت المهمة ضمن مجالها الضيق جدًا. لكن المشكلة أن هذا التفوق لا يمكن تعميمه بسهولة خارج ذلك المجال.
الخلاصة المبسطة: إذا كان السؤال داخل تخصص معين، فقد يكون النموذج المتخصص أفضل من النموذج العام، لكن ليس دائمًا.
4.4 المرتبة الرابعة، النماذج العامة الكبيرة متعددة الوسائط
هذه النماذج قوية جدًا في:
الشرح المبسط
إعادة الصياغة
تلخيص الدراسات
الربط بين أفكار متعددة
التعامل مع نصوص وصور أحيانًا
وهي مفيدة جدًا للمستخدم العادي أو حتى للباحث في المراحل الأولى من الاستكشاف. لكن عند الأسئلة العلمية غير المعروفة الجواب، لا ينبغي الاعتماد عليها وحدها من دون مراجعة الأدلة. بعض الدراسات بينت أن الأداء قد يكون ممتازًا في الاختبارات المهنية أو التعليمية، لكنه لا يضمن الاعتمادية نفسها في مسائل الاستدلال العلمي المفتوح.
الخلاصة المبسطة: هذه النماذج ممتازة للمساعدة والفهم الأولي، لكنها ليست الأفضل وحدها في أصعب الأسئلة العلمية.
4.5 المرتبة الخامسة، النماذج المفتوحة الأساسية غير المتخصصة
هذه النماذج مفيدة حين تكون الأولوية لـ:
الخصوصية
العمل المحلي داخل مؤسسة
خفض التكلفة
التخصيص التقني
لكن إذا تُركت وحدها من دون دعم بالأدوات أو التخصيص العلمي أو المراجع، فإنها تكون عادة أضعف من النماذج الأعلى ترتيبًا في الأسئلة العلمية المعقدة.
الخلاصة المبسطة: مفيدة تقنيًا، لكنها ليست الخيار الأول لمن يريد أفضل إجابة علمية محيرة. - لماذا لا يوجد نموذج واحد “أفضل دائمًا”؟
هذا سؤال مهم جدًا.
السبب أن “الأسئلة العلمية المحيرة” ليست كلها من نوع واحد. فهناك فرق بين:
سؤال له جواب معروف لكن صعب
سؤال له عدة تفسيرات محتملة
سؤال يعتمد على أحدث الأدلة
سؤال يحتاج تحليل صور أو رسوم أو جداول
سؤال ما تزال إجابته غير محسومة أصلًا في العلم
بعض النماذج ممتازة في الأسئلة الامتحانية. بعضها قوي في الاستدلال. بعضها جيد في تخصص ضيق. وبعضها يصبح أفضل فقط عندما نربطه بمحركات بحث وأدوات علمية. لهذا فإن أفضلية النموذج تتغير حسب نوع المهمة. هذا ما تكرره الأدبيات الحديثة بشكل واضح. - ما الذي يجعل نظام ذكاء اصطناعي جيدًا فعلا في العلم؟
من منظور القارئ غير المتخصص، يمكن تبسيط المعايير في خمس نقاط.
6.1 أن يعرف متى لا يعرف
هذه أهم نقطة. الذكاء الاصطناعي الخطير ليس الذي يجيب فقط، بل الذي يجيب بثقة عندما يكون مخطئًا. الدراسات الحديثة حول الهلاوس في التطبيقات الطبية تؤكد أن هذه المشكلة ما تزال حقيقية ومهمة.
6.2 أن يستخدم مصادر حديثة
العلم يتغير بسرعة، خصوصًا في الطب والذكاء الاصطناعي والبيولوجيا الجزيئية. لذلك، النموذج الذي يعتمد على معرفته الداخلية فقط قد يكون متأخرًا عن أحدث الدراسات. الاسترجاع المعزز بالمراجع الحديثة، RAG، أصبح جزءًا أساسيًا من تحسين الإجابات العلمية.
6.3 أن يفرق بين الحقيقة والاحتمال
في العلم، ليس كل شيء إما صحيح أو خطأ. أحيانًا تكون النتيجة “مرجحة”، أو “مدعومة جزئيًا”، أو “ما تزال محل جدل”. النظام الجيد يجب أن يعكس هذا التدرج، لا أن يقدم كل شيء بصيغة يقين مطلق.
6.4 أن يشرح منطقه بوضوح
حتى غير المتخصص يحتاج أن يعرف لماذا وصل النظام إلى هذا الترجيح، وما الأدلة الأقوى، وما القيود، وما مواضع الشك.
6.5 أن يكون متخصصًا عندما يلزم
إذا كان السؤال في الطب أو الكيمياء أو الأعصاب، فوجود طبقة تخصصية أو أدوات تخصصية قد يرفع الجودة كثيرًا. - ما الذي تقوله الدراسات الحديثة بشكل عام؟
يمكن تلخيص الرسالة العامة للأدبيات الحديثة في عبارة واحدة:
الذكاء الاصطناعي الحالي قوي جدًا في المساعدة العلمية، لكنه لم يصل بعد إلى مرحلة الاعتماد الكامل عليه في الأسئلة العلمية المفتوحة أو غير المحسومة من دون إشراف بشري ومراجع خارجية.
بعض الدراسات أظهرت أداءً مذهلًا في اختبارات أكاديمية أو مهنية. وبعضها أظهر تفوقًا في التنبؤ بنتائج ضمن مجالات معينة. لكن دراسات أخرى كشفت حدودًا واضحة، مثل:
ضعف المعايرة
الثقة الزائدة
الهلاوس
الحساسية لطريقة السؤال
تراجع الأداء في المهام الحقيقية مقارنة بالاختبارات المغلقة
لذلك، القول إن “فلان هو أفضل AI علمي” من دون تحديد نوع المهمة يكون تبسيطًا مفرطًا. - النتيجة النهائية المبسطة
إذا أردنا جوابًا واضحًا ومباشرًا للقارئ غير المتخصص، فهو كالتالي:
الترتيب التنازلي الأفضل حاليًا في التعامل مع الأسئلة العلمية المحيرة - الأنظمة الذكية المرتبطة بالمراجع والأدوات والتحقق الخارجي
الأفضل عمومًا، لأنها لا تعتمد على الذاكرة فقط، بل على البحث والمراجعة والتثبت. - نماذج الاستدلال القوية
جيدة جدًا في التحليل المنطقي المعقد، لكنها تحتاج دعمًا بالمصادر والتحقق. - النماذج المتخصصة في مجال معين
قد تكون ممتازة داخل مجالها، خاصة في الطب والكيمياء والأعصاب. - النماذج العامة الكبيرة متعددة الوسائط
مفيدة جدًا للفهم والشرح والتلخيص والاستكشاف الأولي، لكنها ليست الأفضل وحدها في أصعب الأسئلة. - النماذج المفتوحة الأساسية غير المتخصصة
نافعة في الخصوصية والتخصيص، لكنها أضعف عادة في نسختها الأساسية عند التعامل مع الأسئلة العلمية الصعبة. - الخلاصة النهائية
إذا سألت: ما هو أفضل ذكاء اصطناعي للإجابة عن الأسئلة العلمية المحيرة وغير المعروفة أجوبتها؟
فالجواب الأدق هو:
ليس أفضلها برنامجًا واحدًا، بل أفضلها نظام يجمع بين الذكاء الاصطناعي، والبحث في الأدبيات، والأدوات التخصصية، والتحقق من الإجابة.
أما إذا كان لا بد من التبسيط الشديد، فقل:
كلما اقترب الذكاء الاصطناعي من طريقة عمل الباحث الحقيقي، صار أفضل في الأسئلة العلمية الصعبة. - مراجع أساسية
Humanity’s Last Exam, Nature, 2025, حول تقييم النماذج على أسئلة أكاديمية شديدة الصعوبة.
npj Digital Medicine, 2026, حول تقييم الأنظمة الوكيلة المعتمدة على النماذج اللغوية في المهام السريرية.
Nature Communications, 2025, حول قياس قدرات الاستدلال السريري للنماذج اللغوية.
مراجعات PubMed حول RAG الطبي وتحسين الاعتمادية بالمراجع الحديثة.
Nature Human Behaviour, 2025, حول نماذج متخصصة في التنبؤ بنتائج علم الأعصاب.
JAMIA, 2025, حول حدود الضبط الحيوي المتخصص في المهام السريرية.
Nature Machine Intelligence وNature Chemistry، حول النماذج المدعومة بالأدوات في الكيمياء.
دراسات PubMed حديثة عن النماذج العامة في الاختبارات المهنية الطبية.
Communications Medicine وnpj Digital Medicine، حول الهلاوس والسلامة السريرية.


























































